How to Process and Convert Large Shapefiles Efficiently in Node.js
Handling Big Data in Node.js
Converting a small Shapefile to GeoJSON is easy. But what happens when a user uploads a 500MB zipped Shapefile with millions of polygons? Loading it all into memory with JSON.parse() will cause V8 to throw a FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory.
The Solution: Streaming
To process massive geospatial datasets in Node.js, you must use streams. Instead of loading the entire file, you read it chunk by chunk.
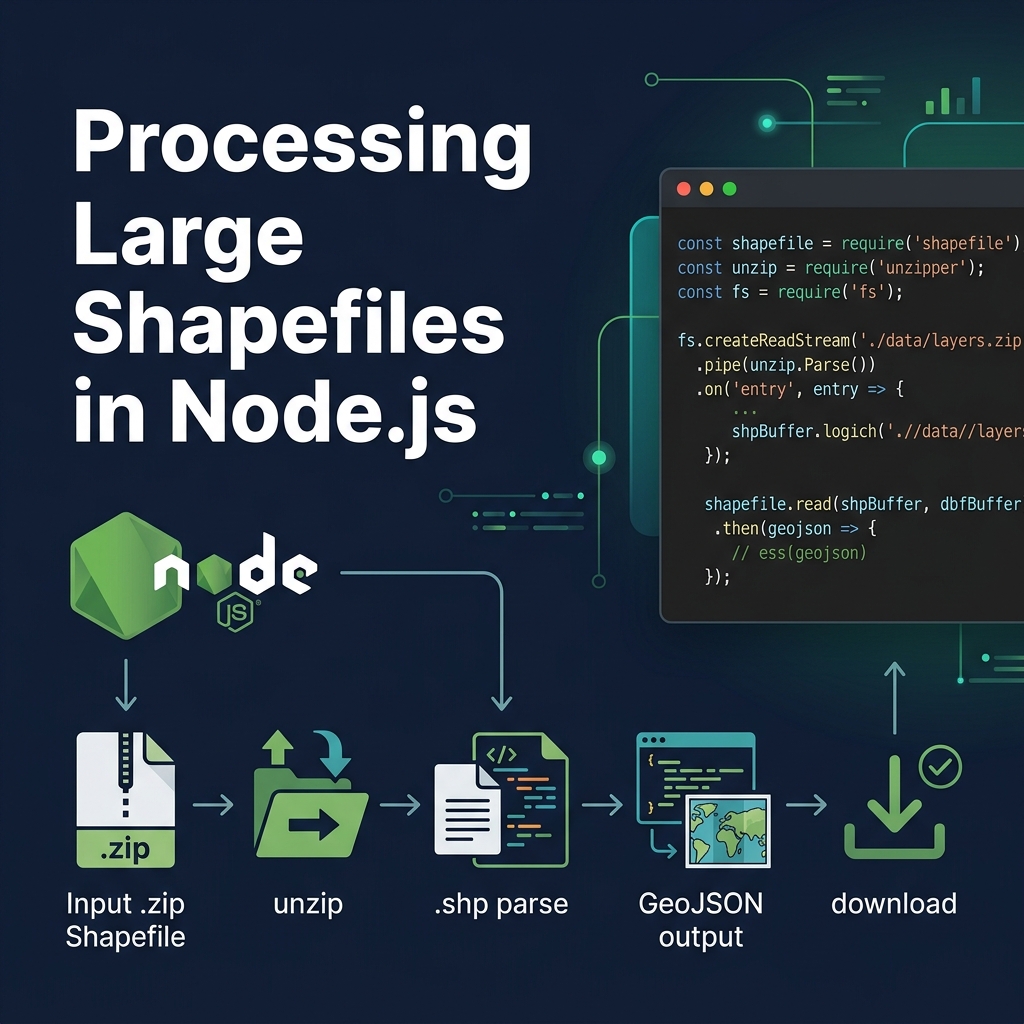
Step-by-step Approach
- Unzip using streams: Use libraries like
unzipperoryauzlto extract the.shpand.dbffiles without loading the zip into memory. - Stream the Shapefile: Use the
shapefilenpm package. Itsopen()method returns a reader that you can iterate over asynchronously. - Write to disk incrementally: Don't build a massive JavaScript array. Instead, open a
fs.createWriteStreamand write the GeoJSON structure manually, streaming each feature into the file.
import shapefile from 'shapefile';
import fs from 'fs';
async function streamToGeoJSON(shpPath) {
const outStream = fs.createWriteStream('out.json');
outStream.write('{"type":"FeatureCollection","features":[');
let first = true;
const source = await shapefile.open(shpPath);
while(true) {
const result = await source.read();
if (result.done) break;
if (!first) outStream.write(',');
outStream.write(JSON.stringify(result.value));
first = false;
}
outStream.write(']}');
outStream.end();
}
This approach uses almost zero RAM, allowing Node.js to process Gigabyte-sized maps efficiently.
GeoSpatial